Slides that Julien showed today concerning the Lovemachine project
Project on Facebook
https://www.facebook.com/lvMchn


L’exercice d’aujourd’hui est de comparer le moteur de recherche de Google avec une moteur de recherche alternatif, d’en comprendre les mécanismes et d’en voir l’incidence sur les résultats générés.
D’un côté nous avons l’omniscient moteur de recherche de Google qui utilise ses propres crawlers pour indexer ses pages internet : il établit par lui-même la pertinence des réponses possibles par rapport à une requête donnée grâce à l’utilisation de nombreux algorithmes en fonction d’une multitude de paramètres comme la popularité du liens, les liens entrants et sortants, etc. Le plus connu est PAGERANK mais il en existe des centaines (voir infographie). Les résultats sont donc hiérarchisés mais il est capable d’en « optimiser » la visibilité, c’est ce qu’on appelle le référencement ou search engine optimization.
Notre comparaison porte sur le moteur de recherche de Wolfram Alpha. Le service, lancé en 2009, se porte comme un outil de calcul en langage naturelle, concrètement c’est un moteur de recherche/computation qui va nous permettre d’apporter une réponse factuelle et synthétique (en anglais) à partir d’une base de connaissances croisée à différentes sources académiques. Le moteur permet, entre autres, d’accéder à plus de 50 000 types d’algorithmes, de couvrir et d’ « analyser les données issues de disciplines très variés, dont les mathématiques, statistiques, analysée de donnée, physique, chimie, science des matériaux, ingénieries [..] linguistique, culture, médias, etc».
Utilisation et pertinence.
Bien qu’il soit possible avec Wolfram Alpha de comparer deux propositions, nous avons choisis de prendre la suggestion aléatoire suivante : mpemba effect. Contrairement à Google, Wolfram Alpha renvoie ne renvoie pas de liens (les sources sont accessibles en bas de page) mais une réponse unifiée à partir d’un croisement de données et de connaissances. Il existe pour la recherche de papiers académiques une variante, Google Scholar. Plus long, le moteur de recherche propose même des hypothèses sur un phénomène physique.

Query “mpenba effect” sur Wolfram Alpha

Query “mbempa effect” sur Google France
Google renvoie comme on peut l’attendre à une myriade de liens correspondant à l’observation de ce phénomène, Wikipédia arrive comme souvent en tête de gondole. Du côté de Wolfram, la réponse s’organise en plusieurs rubriques. On y trouve notre requête, une description assez succinte en premier lieu : “sous certaines conditions, un volume d’eau chaude aura tendance à geler plus vite qu’un volume d’eau froide [..]”.
Un encart « histoire » nous permet de remonter à la première occurrence historique de l’effet à 1963 (51 years ago) par son homonyme Erasto Mpemba. On retrouve aussi une filiation historique avec d’autres hommes: Aristote, Bacon, Descartes.. Le moteur va plus loin encore en proposant des indications. Il nous suggère par exemple dans la rubrique «current evidence» que l’effet peut être influencé par un “nombreux infini de paramètres expérimentales”, il ajoute également que les causes du /mpemba effect/ n’a pas encore été résolu. Plus qu’un moteur de recherches comme Google qui renvoie une liste de pages indexées en fonction des mots-clés, Wolfram Alpha va jusqu’à émettre des hypothèses et un jugement par rapport à une proposition donnée. En comparant de façon assez sommaire avec les informations disponibles sur la page de Wikipédia, la réponse semble avoir un certain degré de vérité. Évidement, ni l’un ni l’autre ne sont la preuve d’une vérité absolue, mais les deux nous offrent néanmoins un aperçu du problème.
Derrière les réponses.
Les sources nous renvoient à une série de sites académiques mais nous révèle aussi l’existence d’une source d’informations principales : la Wolfram|Alpha Knowledgebase, 2014. Après quelques requêtes supplémentaires sur cette base de données, le moteur nous renvoie :

La réponse peut donc sembler à la fois surprenante et un poil arrogante, à savoir comment est constitué cette « base de données de savoirs et connaissances » auto-proclamé car on se retrouve donc avec Wolfram Alpha plus qu’un simple moteur de recherche mais bien une volonté de bases de connaissance quasiment encyclopédique, mais dont les réponses seraient rédigé par des algorithmes.
Le site nous permettra en effet de faire de l’algèbre, des statistiques ou de générer la visualisation d’une requête. Les domaines de connaissances sont en cours d’élaboration depuis le lancement du site et ne cessent de s’enrichir. Wolfram Alpha est utilisé pour améliorer les résultats des moteurs de recherche de Bing ainsi que DuckDuckGo.
Andréa Mancini et Léo Seyers.
moteur de recherche : YACY
YaCy est un moteur de recherche que chacun peut installer pour indexer le web (pages publiques accessibles par internet), pour indexer un intranet ou pour parcourir d’autres données avec une fonction moteur de recherche. YaCy peut être utilisé de façon autonome, mais sa principale force est de pouvoir fonctionner en réseau peer-to-peer, ce qui fait que sa puissance s’accroit avec le nombre d’utilisateurs, qu’il est entièrement acentré (tous les “peers” sont égaux et il n’y a pas un organisme administratif central) et qu’il n’est pas censurable et ne stocke pas le comportement des utilisateurs.
La liberté de l’information ainsi obtenue par le biais des logiciels libres et d’un moteur de recherche distribué est également un des objectifs du projet.
Qwant est un moteur de recherche français mis en place en 2013.
![]()
Il se présente comme Google à quelque détails près
↓

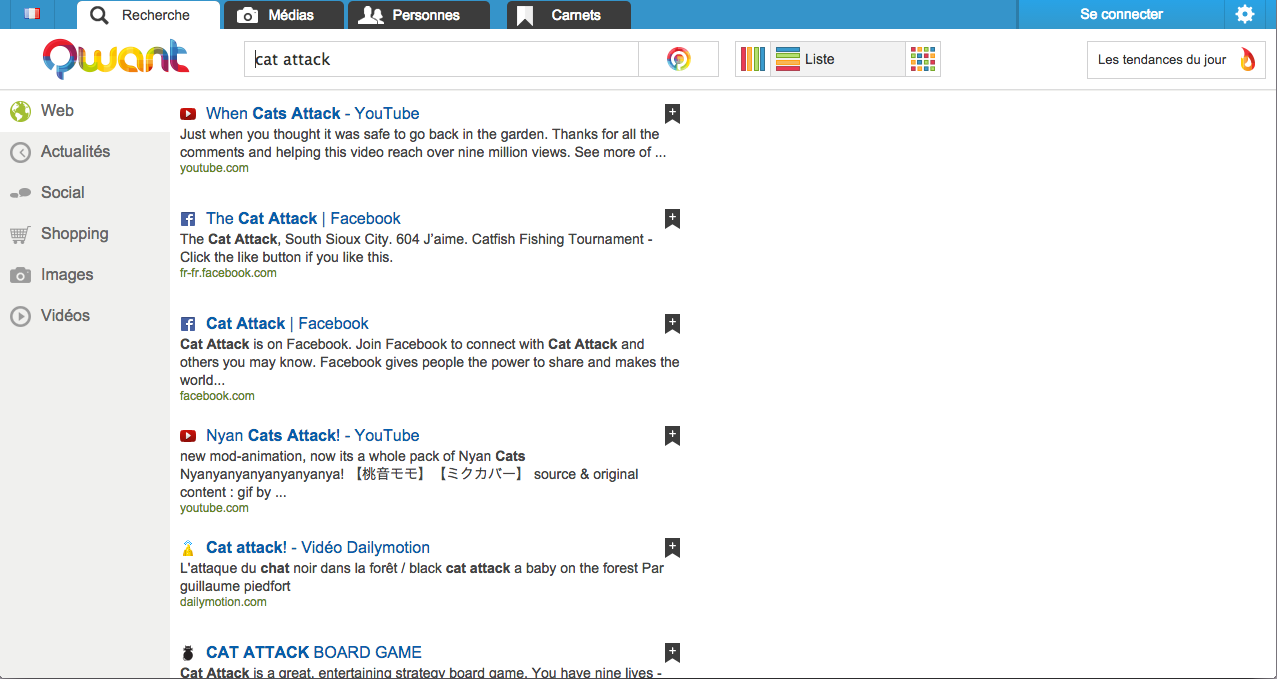
L’interface de Qwant est efficace, en effet elle propose une meilleure classifications des informations par le biais de code couleurs. Les catégories sont pertinentes (Web, Actualités, Social, Shopping, Images, Vidéos, Médias) et il est possible de changer la structure (par liste, par colonne, par grille)
↓

Exemple avec grille
—
Sur Google, les publicités ne sont pas mise en évidences.
Qwant quand à lui, utilise le code couleur jaune, l’utilisateur n’est pas trompé
—
Les index de Google sont tout de même plus fournis.
 → Les sources vidéos de Qwant / 3
→ Les sources vidéos de Qwant / 3
 → Les sources vidéos de Google / 6
→ Les sources vidéos de Google / 6
—
Tout comme le principe du “google +” Qwant possède ses “carnets” et donc la possibilité de suivre des personnes ou entreprises. Qwant mise sur l’aspect visuel, tout comme Pinterest.
↓

—
Sara & Céline
This is two South Korean search engines. We search with the words “Kim Jung Il”.
This is the result:
Daum
http://en.wikipedia.org/wiki/Daum_Kakao
http://search.daum.net/search?w=tot&DA=YZR&t__nil_searchbox=btn&sug=&o=1&q=kim+jung+il
Naver


http://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/assange/#images
Artistgroup Bitnik made a contemporary mail-art work: they sent a package to Julien Assange, a camera and gps tracker hidden in the package registered the trajectory from inside the parcell.
Million short est un moteur de recherche qui ignore les sites les plus populaires.
À l’inverse de google qui propose les liens les plus populaires et les liens le plus rechercher million short propose de découvrir d’autres liens les moins populaires .cependant il y a aussi la possibilité de cachés cette fonction et de l’utiliser comme google.
il propose d’ignorer par paliers les 100, 1000, 10 000, 100 000 ou le 1er million des résultats habituels. L’option « manage setting« permet aussi de filtrer les résultats en incluant ou excluant les sites de son choix ou d’afficher prioritairement en tête des résultats de sites à privilégier.
En terme de base de données, Million Short utilise principalement le moteur de recherche Google… Tout en essayant de montrer sa différenciation via les options mentionnées ci-dessus.
exemple:
j’ai recherché un site très populaire Facebook dans million short et on voit bien qu’a l’inverse des autres moteurs de recherche il proposes des liens beaucoup moins courants.

alors que si je recherche facebook sur google j’ai directement le liens du site officiel de facebook

on trouve même ici une vidéo concours entre google et millionshort

Яндекс (lecture : “Yandex”) est un moteur de recherche russe. Il est assez similaire à Google avec une interface assez proche.
Les menus sont à gauche pour le contenu web, images, vidéos, maps et market.
D’autres fonctions sont accessibles en survolant avec le curseur le logo du moteur de recherche.
La disposition est donc très similaire à Google.
Sur Yandex, lorsqu’on recherche son ip, le résultat s’affiche ici :
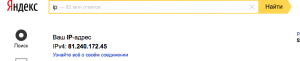
Pas sur Google 😉
Aussi, si on clique sur le carré au trois curseurs sur la droite. Des paramètres apparaissent tels que les filtres de modération (tout type de contenu, modéré, familial). Dans le second onglet, des filtres de durée pour les pages (postée depuis 2 semaines, 1 semaines, deux jours, .. ). Troisième onglet, les langues de recherche (russe, anglais, français, … ). Et dans le dernier, les types de format voulu (pdf, rtf, ppt, … ).
Le site propose dans ses paramètres une lecture sans AJAX :
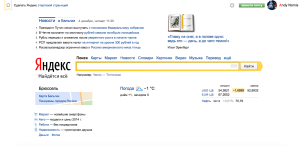
La page d’accueil Google propose des raccourcis pour faciliter les recherches et Yandex donne des infos d’actualités du type météo, valeurs boursières, …

La possibilité de se loguer est identique à Google.
Yandex propose aussi de nombreux petits add-on comme un dictionnaire, l’accès aux actualités, des photos aléatoires sur 500px, une option de traduction similaire au Google Translate, annonces immobilières, …
C’est un moteur plus proche de Yahoo.
/wp-content/uploads/GunesAcarPresentation.pdf
How do search engines work
http://www.google.com/insidesearch/howsearchworks/thestory/
/?p=336
http://en.wikipedia.org/wiki/Web_search_engine
https://en.wikipedia.org/wiki/robots.txt
http://www.google.com/robots.txt
http://constantvzw.org/robots.txt
https://archive.org/robots.txt
Discover new search engines:
http://en.wikipedia.org/wiki/List_of_search_engines
Make 1 post on the blog with: Try to find a search engine we do not know. Use it to search, and compare the results to the results you find in to G**gle search and analyse !

On tuesday 20 november 2014 we visited the worksession Gender Blending, organised by Constant in De Beursschouwburg.
We did a ‘Gender Turing test’ to conceil and / or retrieve gender in the imagined context of a chat. The excercise was prepared by ginger coons, who did the workshop in the context of this years Pink Screens festival.
{kind=link}
{kind=link}